Introduction
If you are a developer you may at least one time use version control such as: GIT, BITBUCKET, SVN… and i think GIT will be the first choice among these tools. Have you ever wonder why GIT is so common like that? What is the power behind GIT?, etc. Today you and I will discover the secret of GIT and after this article you won’t scare GIT anymore. Let’s get started
Git object types
When talk about GIT, we should only care about three things: BLOB, TREE and COMMIT. All of them will be compressed into a SHA-1 before being stored to git database.
SHA stands for Secure Hash Algorithm. A SHA creates an identifier of fixed length that uniquely identifies a specific piece of content. SHA-1 succeeded SHA-0 and is the most commonly used algorithm. Wikipedia (http://en.wikipedia.org/wiki/SHA1) has more on the topic.
Let’s dive deep into each type
BLOB
In Git, BLOB store content of a file. I must emphasize that a content of a file not the file’s name. It means if you have 2 files with the same content but in the different place, Git only store 1 blob. For instance, I create 2 files test1.txt and test2.txt with the same content is Hello world
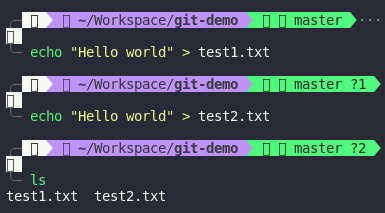 Let’s
Let’s git add to see how git store those files.
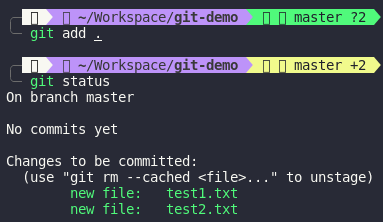
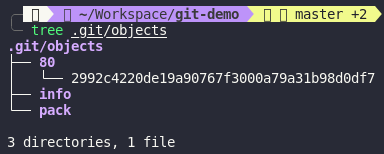 As we can see, when I add those files, Git only store 1 blob with SHA-1 is
As we can see, when I add those files, Git only store 1 blob with SHA-1 is 802992c4220de19a90767f3000a79a31b98d0df7 in .git/objects. We will talk more about .git folder in the next section but basically it’s Git’s database. Let’s try to add test3.txt with content is Hello world demo
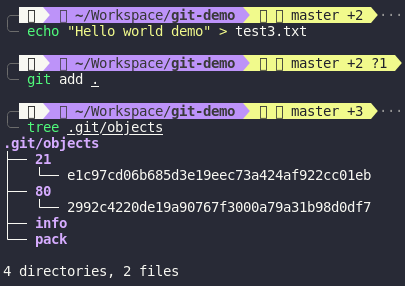 Since the content of
Since the content of test3.txt is different from test1.txt and test2.txt so Git will store content of test3.txt in another blob with SHA-1 is 21e1c97cd06b685d3e19eec73a424af922cc01eb
TREE
Tree in Git is similar to a directory in operation system. Directory contains files and other directories, tree contains blob and other trees
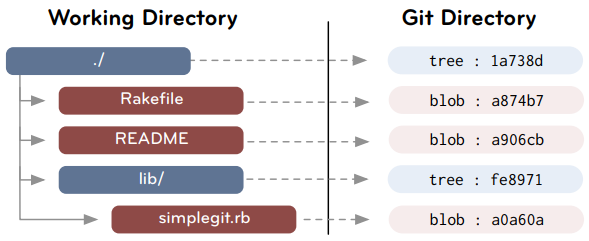 (Update image from canva later)
(Update image from canva later)
Like I mentioned above, TREE also have its own SHA-1
COMMIT
Commit is a snapshot of our working directory. It points to a tree and contains some information such as: author, message, parent, etc. Also like BLOB and TREE, COMMIT have its own SHA-1. Let’s back to our working directory.
In the last examples, we have created 3 files test1.txt, test2.txt and test3.txt.
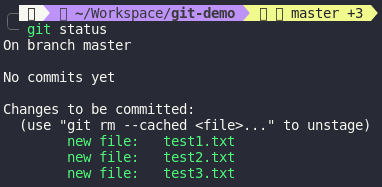
Currently, those files still in staging area (where files are prepared for next commit but we will discover it later on). If we want to move those files to our repository, we should use git commit
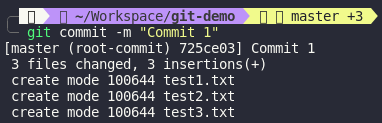

You can see that I’ve already created a commit with the message is Commit 1 and its SHA-1 is 725ce03ca79fff4314c183eac0110ea279344188
Git data model
Now we’ve already known Git’s object types. Let’s take some example to be more clearly
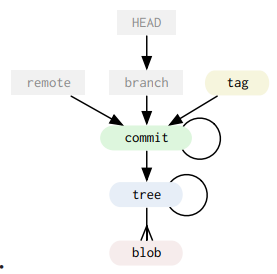 Here is a graph to visualize relationship between those object types. In this section, I won’t talk about HEAD, branch, remote, tag, only focus on blob, tree and commit.
Here is a graph to visualize relationship between those object types. In this section, I won’t talk about HEAD, branch, remote, tag, only focus on blob, tree and commit.
For example, I have a directory like this
Let’s commit those files to see what happen
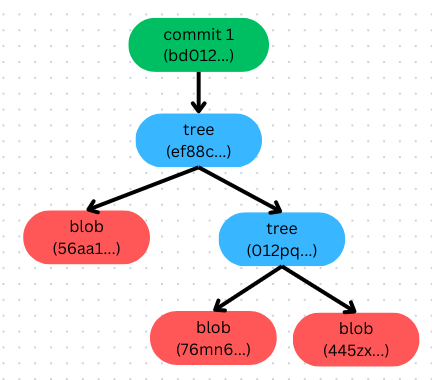 Take a look at this graph, we can see that, Git structure our commit quite similar to working directory. The
Take a look at this graph, we can see that, Git structure our commit quite similar to working directory. The tree(ef88c...) node is a snapshot of our working directory and commit(bd012...) node will point to tree(ef88c...) node. Now let’s assume that I change the index.js file and commit again
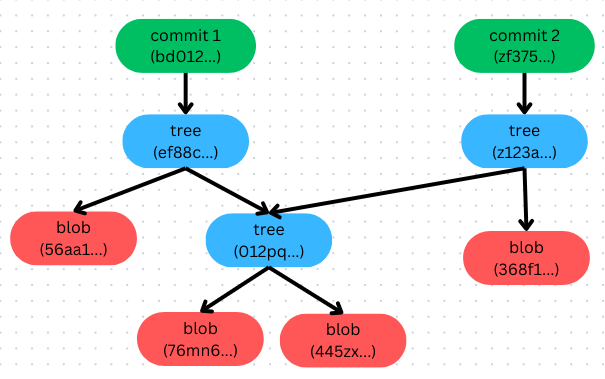 Since the content of
Since the content of index.js has changed so its SHA-1 also been changed. That why git create another blob. One thing we should notice here is that why Git won’t create another blob of config.js and database.js?
It’s quite easy to figure out from index.js.
index.js=> Content changed => SHA-1 changed => New blobconfig.js=> Content remain => SHA-1 remain => Old blobdatabase.js=> Content remain => SHA-1 remain => Old blob
Since the content of config.js and database.js didn’t change, Git only need point the tree(z123a...) to tree(012pq...).
How about delete config.js?
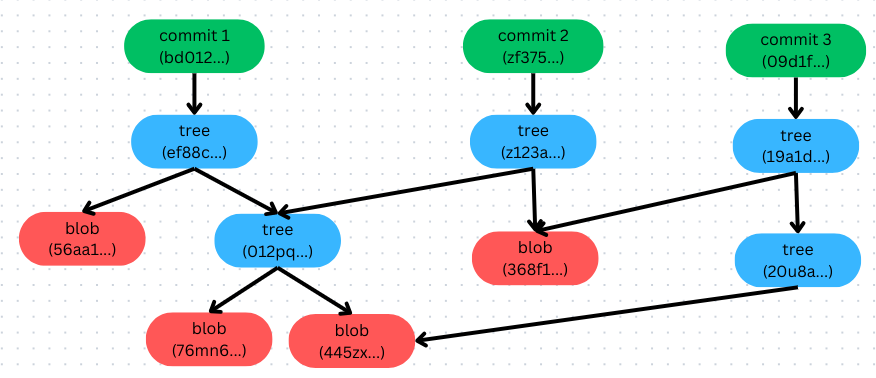
Let’s repeat above steps
index.js=> Content changed => SHA-1 changed => New blobdatabase.js=> Content remain => SHA-1 remain => Old blobconfig.js=> Deleted => No blob
Notice that SHA-1 of tree(012pq...) made from SHA-1 of blob(76mb6...) and blob(445zx...) so any of those blob changed lead to change SHA-1 of tree. Since we deleted config.js so Git will create another tree that only need to point to blob(445zx)(database.js). The cool thing here is that even thought we deleted config.js but it’s actually still being stored in Git database. When we back to commit 1 or commit 2, we can still get config.js.
.git folder
Have you ever tried to figure out what inside of it? If not, try with me.
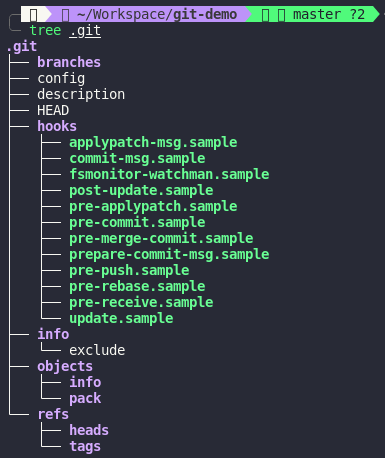
Here is what inside .git folder. We should care about 3 things: objects, refs and HEAD.
objects
As I mentioned early, objects just like a database of Git, it store blobs, trees and commits.
Let’s create a commit
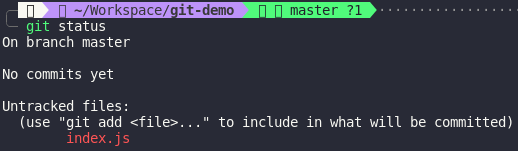
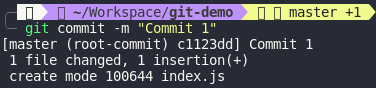
Done. We’ve already create a commit. Let’s what happened inside objects folder
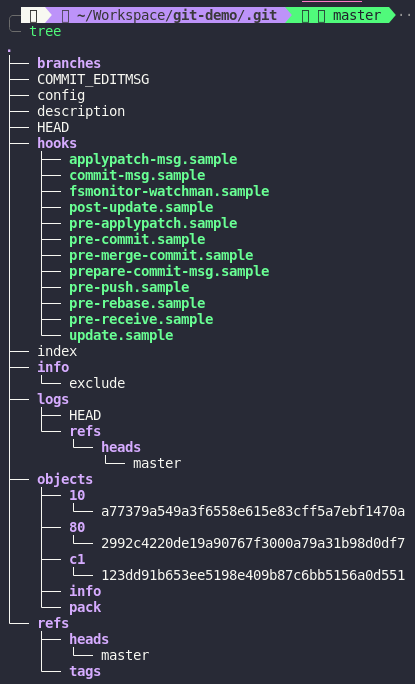
As you can see, after we created a commit. There are 3 folders and 3 files appear in objects folder. These are basically Git’s objects. Let’s back to our previous commit
 The SHA-1 of the commit is
The SHA-1 of the commit is c1123dd and it’s similar to path c1/123dd.. in objects folder. I think you can figure out that is where Git store our commit. If you remember, we all know that commit point to a tree and tree point to other tree and blob. So where is our tree and blob in the objects folder. Git provide us a cool low-level command to interact more with Git is git cat-file. Let’s try with our commit first
| |
This is the content of our commit
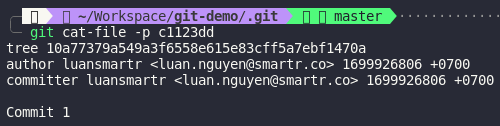 It shows that
It shows that author and committer is me, commit’s message is Commit 1 and the tree that the commit is pointing to.
Try one more time with a tree
| |
This is the content of the tree
 It shows that the
It shows that the tree is pointing to a blob and that is our index.js file.
Finally, let’s see what inside the blob
| |
 Nothing surprise,
Nothing surprise, blob is only store the content of index.js file.
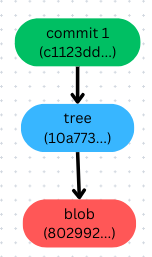
Let’s recap with a graph for easy to understand
refs
When working with Git, we will face with the term branches a lot. So what is branches?
Branches is nothing but a reference name of the latest commit. Back to our terminal, let’s see what is our current branch
| |
 See that our current branch is
See that our current branch is master. But where does Git store branches? It’s refs folder. Let’s take a look at refs folder.
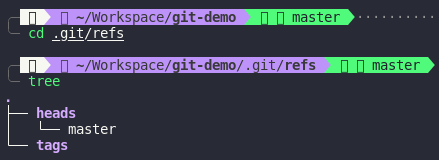 In
In refs folder, Git store 2 things: heads and tags
- heads is where Git store branches
- tags is where Git store tags
Technically, both branches and tags are pointing to a commit.

Can you figure out what is the content of this file? Yes, that in the SHA-1 of Commit 1.
How about create new branch?
 The same with
The same with master branch, the new-branch still store the SHA-1 of Commit 1.
Quick recap
Branches is nothing but a reference name to the latest commit
HEAD
There is a mystery that you and I wonder when first time using Git: “How Git now what is our current branch?”. After a bunch of researches, i’ve known that Git uses a special pointer called HEAD to keep track of branches. Back to the .git folder
There is a file called HEAD. If we cat that file, we can see that it basically store a path which references to a branch

It’s important to notice that the main idea of HEAD is pointing to a commit. The common pattern we see is HEAD => branches => commit. Since the branches point to a commit so HEAD points to branches is the same for HEAD points to commit. But in some case, HEAD can directly point to a commit, this case we call detached mode.
Recap
In this article, I’ve already show you behind the scene of Git. From now on, when take about Git we should only care about BLOB, TREE and COMMIT. We also know what HEAD pointer is, in next article i will dive deep into HEAD pointer so that we won’t scare it anymore. It’s quite long for this article, i hope that you can get useful information from it. See you in my next article.